JavaScript 不是 SEO 的敵人。真正麻煩的地方,在於很多團隊會不自覺地假設:只要頁面在瀏覽器裡看起來沒問題,搜尋引擎也一定看得到同樣內容。這件事其實沒那麼穩。
這篇文章不是只談原理,而是回到一個很直接的實驗:做一個幾乎把核心內容都交給 JavaScript 客端渲染的頁面,然後觀察 Google、Bing、Yandex 分別怎麼抓、怎麼顯示、多久才更新。
如果你平常在做 React、Vue、Next.js、Nuxt,或任何以 CSR 為主的前端架構,這個問題其實非常貼身。若你想先確認搜尋引擎實際拿到的是什麼,SEO Analyzer 可以先幫你檢查 initial HTML 和技術訊號有沒有缺關鍵東西。
先講最重要的背景:兩階段索引
Google 對這類 JS 頁面,常常不是一次做完,而是分兩輪:
- 先抓 initial HTML,做第一輪索引。
- 等到渲染資源輪到這頁,再執行 JavaScript,重新看最終 DOM。
這個差別很要命。因為如果你的核心內容只在 JS 執行後才出現,它就不會出現在第一輪。
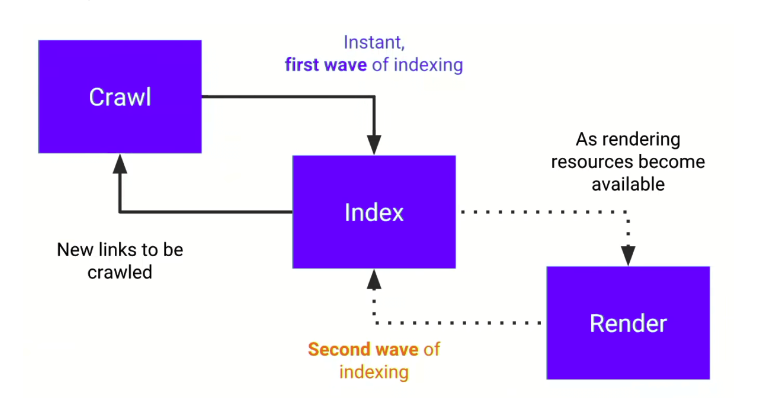
這也是為什麼有些頁面剛進索引時,title 或 snippet 看起來很怪,過幾天才慢慢修正。
這次實驗頁面怎麼設計
測試頁刻意做得很極端:
- 初始 HTML 幾乎是空的
title、H1、meta description、主體文字都靠 JS 塞進去- 內容透過 AJAX 載入
Articleschema 也用 JS 注入
換句話說,如果搜尋引擎不執行 JavaScript,它能讀到的有用內容非常少。
1$(document).ready(function () { 2 $.ajax({ 3 url: '/api/get-article-data', 4 success: function(data) { 5 $('title').text(data.title); 6 $('h1#main-title').text(data.h1); 7 $('meta[name="description"]').attr('content', data.description); 8 $('#article-content').html(data.body); 9 10 var script = document.createElement('script'); 11 script.type = 'application/ld+json'; 12 script.text = JSON.stringify(data.schemaData); 13 document.head.appendChild(script); 14 } 15 }); 16});
故意把初始 HTML 和最終 DOM 做得差很多,這樣只要看搜尋結果變化,就能很清楚知道搜尋引擎到底有沒有走到第二輪。
Google 的工具看得到什麼
先不急著看 SERP,本地工具與官方工具本身就已經給了不少線索。這個案例裡,Google 的 Rich Results Test 可以正常產生最終 DOM,也能抓到 JavaScript 後注入的資料。
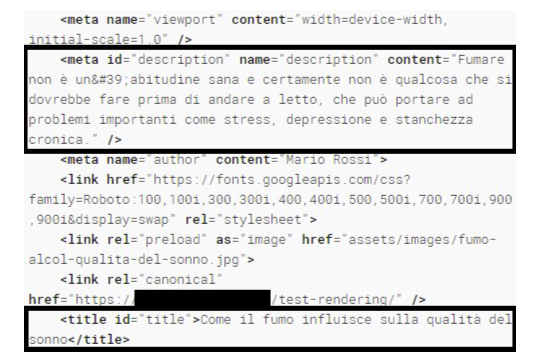
這代表 Google 在技術上是看得懂這頁的。但「看得懂」不代表「馬上就會反映到索引與 SERP」。
第一輪結果:一開始 SERP 顯示了什麼
在提交後幾個小時內,Google、Bing、Yandex 都已經能搜到這頁。但顯示出來的標題與描述,依然是初始 HTML 裡那點內容,不是 JS 渲染後的版本。
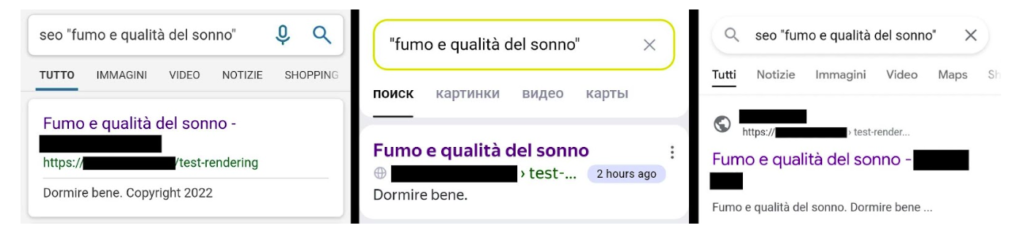
這其實就是兩階段索引最直觀的樣子。頁面已經進索引了,但還不是你希望搜尋引擎最終理解的那個版本。
如果你做的是下列情境,這種延遲尤其麻煩:
- 新上線 landing page
- 新聞或時效型內容
- 需要快速更新 title 與 description 的頁面
- 很依賴早期收錄速度的專案
第二輪:Google 最後還是會追上,但不快
幾天之後,再用 site: 搜尋時,已經看得到原本只存在於 JS 渲染後的文字。這代表 Google 確實把第二輪渲染結果帶進索引裡了。
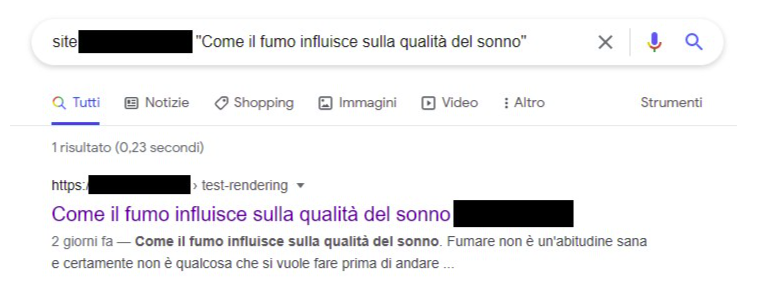
實務上這代表什麼?代表 Google 確實能處理 AJAX 加載、客端渲染的內容,但它不一定會立刻做。
對某些站來說,慢幾天沒差。對另外一些站來說,這就是風險。
Bing 和 Yandex:差距在這裡變得很明顯
同一段期間裡,Bing 和 Yandex 顯然更依賴 initial HTML。它們沒有像 Google 一樣明顯地跟上最終渲染內容。
這件事很重要,因為很多團隊其實只用 Google 的能力來假設所有搜尋引擎。真實世界不是這樣。不同引擎對 JS 的容忍度與處理能力,差異還是很大。
後備做法:Dynamic Rendering
接著又試了一個常見折衷方案:dynamic rendering。
- 一般使用者拿到正常的 JS 頁面
- crawler 則拿到已經預先渲染好的 HTML
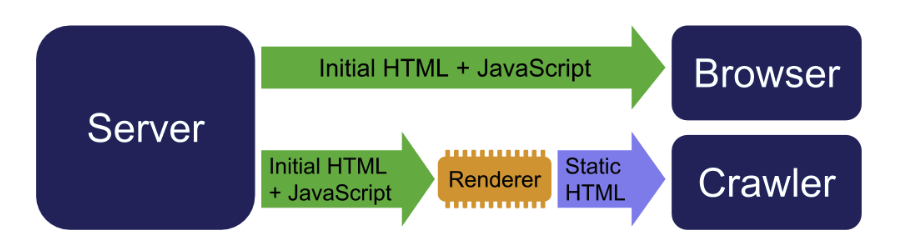
啟用之後,Yandex 的 snippet 就跟著更新了,開始採用預渲染版本的內容。

這不代表 dynamic rendering 是所有新專案的最佳解。它只是很清楚地說明一件事:只要搜尋引擎早點拿到可直接閱讀的 HTML,問題通常就會少很多。
這個實驗真正說明了什麼
1. Google 會渲染 JS,但這不等於 SEO 沒風險
最常見的誤解是:「Google 反正會 render JS,所以放哪都沒差。」
實際上不是這樣。因為:
- 渲染有排隊
- 索引更新有延遲
- 每頁不一定都以同樣速度處理
- initial HTML 沒有的內容,SEO 即時性就會變差
2. Initial HTML 還是最穩的保險
如果頁面對 SEO 很重要,最好讓這些元素一開始就出現在 HTML 裡:
<title>- meta description
- H1
- 主要文字內容
- 重要導覽與內鏈
- 關鍵結構化資料
這樣不只 Google 比較穩,其他搜尋引擎也比較不容易出事。
3. SSR 與 SSG 還是更穩的做法
如果技術條件允許,SSR 或 SSG 依然是做 SEO 關鍵頁面時比較放心的方案。不是說 CSR 完全不能用,而是你不該把 title、description 與核心內容都交給一個可能延遲的第二輪渲染。
4. Dynamic Rendering 比較像過渡方案
對舊系統、歷史包袱重的專案,它很有用。但對新專案來說,它通常不是最乾淨的終點。因為它會增加維運複雜度,也要更小心避免 bot 版與 user 版差太多。
給 SEO 與前端團隊的實務建議
把這次實驗濃縮成工作原則,大概就是:
- 不要把 SEO 核心內容完全押在 CSR 上。
- 永遠確認 crawler 實際拿到的 HTML。
- 如果收錄速度很重要,優先考慮 SSR 或 SSG。
- 把 CSR 留給互動層,不要留給語意主體。
- 只有在現實架構真的卡住時,再考慮 dynamic rendering。
在上線前的檢查流程裡,可以先用 SEO Analyzer 看 initial HTML 有沒有把關鍵東西送出去,再用 Meta-Tag Generator 把 snippet 相關訊號補穩。
結語
這個實驗不是在說 JavaScript 不適合 SEO。它真正說的是:如果你把頁面最重要的 SEO 資訊都延後到 client-side render 之後才出現,那你就是把索引速度、搜尋引擎一致性和可預測性一起拿去冒險。
如果你只想記一條規則,那就記這條:互動效果可以交給 JavaScript,但 SEO 的核心語意,盡量從第一個 HTML 回應就先交出去。這通常是最穩的。