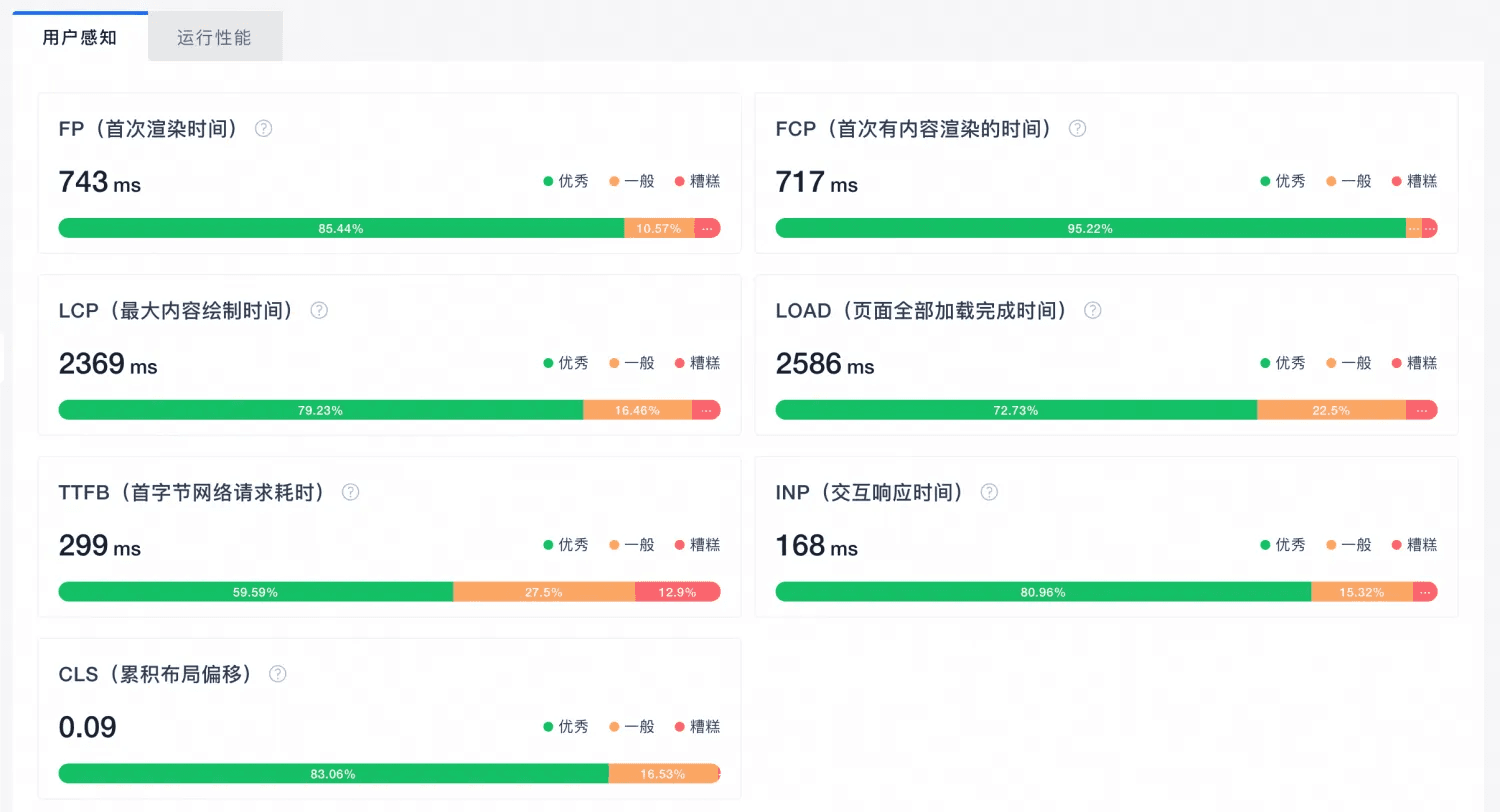
JavaScript nao e o vilao do SEO. O problema comeca quando o time presume que, se a pagina abre bem no navegador, os buscadores vao entender tudo do mesmo jeito. Na vida real, nao funciona assim.
Este artigo parte de um experimento bem direto: uma pagina onde titulo, descricao, texto principal e outros sinais importantes dependiam quase totalmente de JavaScript no cliente. A ideia era descobrir o que cada buscador enxergava primeiro, o que demorava para aparecer e onde estavam os limites mais claros.
Se voce trabalha com React, Vue, Next.js, Nuxt ou qualquer stack com CSR forte, esse tema nao e teorico. E se quiser conferir o HTML que o crawler realmente recebe antes de publicar, SEO Analyzer ajuda a comparar saida inicial, sinais tecnicos e pontos de risco.
O basico que muita gente ignora: two-wave indexing
O Google normalmente nao processa uma pagina cheia de JavaScript de uma vez so. O fluxo costuma ser:
- rastrear e indexar o HTML inicial
- renderizar o JavaScript depois, quando houver recurso disponivel
Isso muda bastante o jogo. Se o conteudo principal so aparece depois do JS, ele fica fora da primeira rodada.
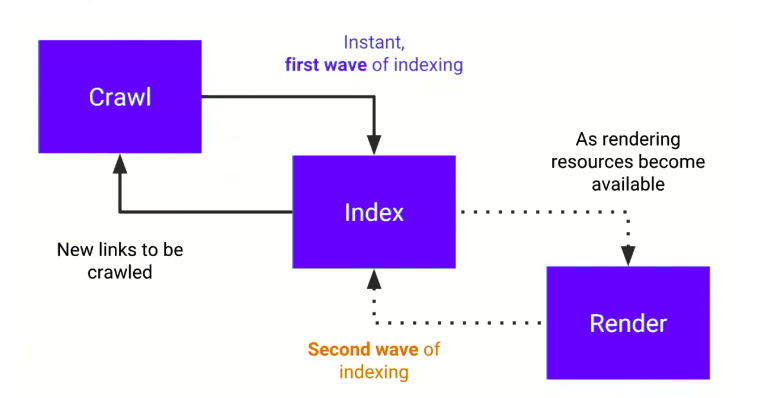
E e justamente dai que surgem snippets estranhos, titulos incompletos e indexacoes "meio certas" que so melhoram dias depois.
Como o teste foi montado
A pagina de teste foi criada para ser extrema de proposito:
- HTML inicial minimo
title,H1, meta description e corpo principal inseridos por JavaScript- conteudo carregado via AJAX
- schema
Articleinjetado por JS
Ou seja: sem executar JavaScript, o buscador tinha muito pouco material util.
1$(document).ready(function () { 2 $.ajax({ 3 url: '/api/get-article-data', 4 success: function(data) { 5 $('title').text(data.title); 6 $('h1#main-title').text(data.h1); 7 $('meta[name="description"]').attr('content', data.description); 8 $('#article-content').html(data.body); 9 10 var script = document.createElement('script'); 11 script.type = 'application/ld+json'; 12 script.text = JSON.stringify(data.schemaData); 13 document.head.appendChild(script); 14 } 15 }); 16});
O desenho foi pensado para deixar muito clara a diferenca entre o HTML bruto e o DOM final. Assim, qualquer mudanca na SERP viraria evidencia de renderizacao real.
O que as ferramentas do Google conseguiram enxergar
Antes de olhar os resultados de busca, ja dava para testar a capacidade de renderizacao. O Rich Results Test do Google conseguiu montar o DOM final e ler os elementos que so apareciam depois da execucao do JavaScript.
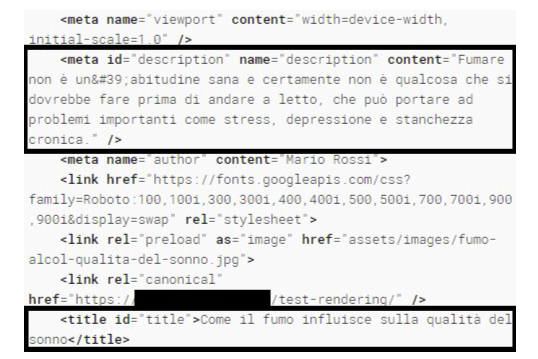
Isso prova que o Google consegue ler esse tipo de pagina. Mas "consegue ler" ainda nao significa "vai usar isso agora".
Primeira etapa: o que apareceu no comeco
Poucas horas depois do envio, a pagina ja aparecia em Google, Bing e Yandex. O detalhe importante e que os snippets vinham do HTML inicial, nao do conteudo renderizado depois.
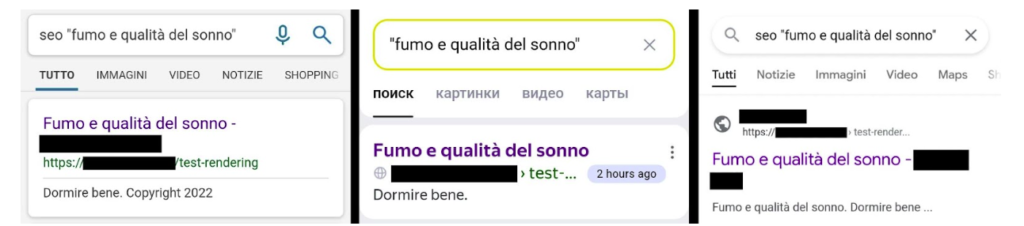
Esse e o retrato mais claro da primeira onda de indexacao. A URL esta no indice, mas ainda nao com a versao "real" da pagina que o usuario enxerga no navegador.
Para SEO, isso pesa principalmente em:
- paginas novas que precisam andar rapido
- conteudo de noticia ou campanha
- mudancas de titulo e description que nao podem demorar dias
- projetos que dependem de descoberta rapida
Segunda etapa: o Google chega la, mas leva tempo
Alguns dias depois, uma busca site: ja mostrava texto que originalmente so existia no conteudo renderizado por JavaScript. Ou seja: o Google tinha feito a segunda leitura e incorporado o DOM final.
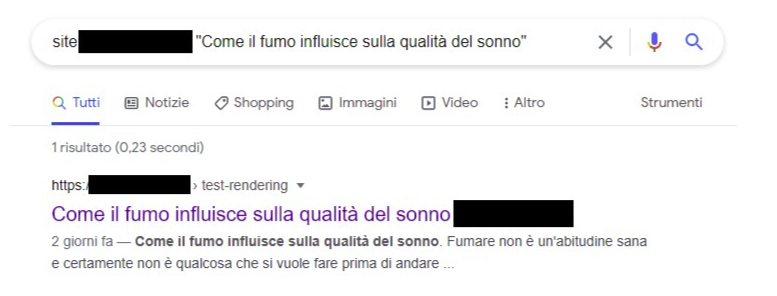
Na pratica, isso mostra que o Google consegue lidar com conteudo carregado por AJAX e montado no cliente. So que existe fila, existe atraso e existe incerteza de tempo.
Para alguns cenarios, tudo bem. Para outros, isso vira um custo desnecessario.
Bing e Yandex: e aqui que a diferenca aparece
No mesmo teste, Bing e Yandex ficaram muito mais presos ao HTML inicial. O comportamento foi claramente mais limitado do que o do Google.
Isso importa bastante se seu projeto nao depende so de Google, ou se voce atua em mercados onde outros motores ainda tem relevancia real. Em ambientes assim, jogar o conteudo principal todo para o cliente e pedir problema.
O fallback: dynamic rendering
Como etapa extra, foi configurado dynamic rendering:
- usuario normal recebe a pagina com JS
- crawler recebe uma versao HTML pre-renderizada
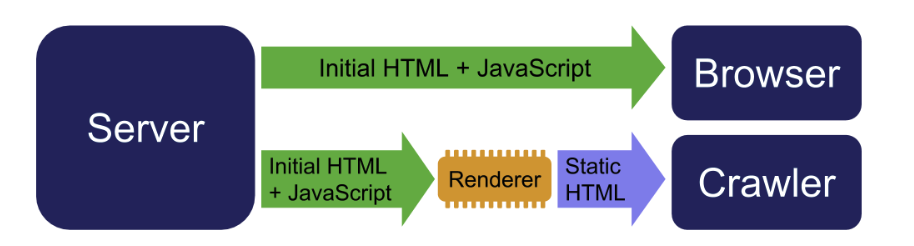
Depois disso, o Yandex passou a atualizar o snippet com o conteudo pre-renderizado.

Isso nao significa que dynamic rendering seja a solucao ideal para todo projeto. Mas mostra algo que SEO tecnico ja sabe faz tempo: HTML pronto ainda reduz muito atrito para os buscadores.
O que esse teste deixa claro
1. O Google renderiza JavaScript, mas isso nao elimina o risco
Muita gente transforma "Google renderiza JS" em "entao tanto faz onde o conteudo nasce". Nao e a mesma coisa.
O Google renderiza, sim. Porem:
- existe fila
- existe delay
- nem toda pagina e processada no mesmo ritmo
- o que fica fora do HTML inicial perde velocidade de indexacao
2. O HTML inicial continua sendo a camada de seguranca
Se a pagina importa para SEO, estes elementos deveriam idealmente sair no HTML inicial:
<title>- meta description
- H1
- texto principal
- links importantes
- schema relevante
Isso da mais estabilidade entre motores e reduz dependencia da segunda onda.
3. SSR e SSG ainda sao as opcoes mais tranquilas
Se houver margem tecnica, SSR ou SSG continuam sendo os caminhos mais seguros para conteudo importante. Nao porque CSR seja proibido, mas porque nao faz sentido colocar titulo, description e corpo principal numa fila de renderizacao se isso puder ser evitado.
4. Dynamic rendering e mais gambiarra util do que destino final
Ele pode salvar projeto legado, replatform dificil ou stack que nao vai mudar tao cedo. Mas adiciona complexidade operacional e exige cuidado para nao abrir margem para inconsistencias ou cloaking mal resolvido.
Recomendacoes praticas para times de SEO e front-end
Se quiser resumir em poucas decisoes:
- Nao esconda conteudo SEO critico atras de JS cliente.
- Teste sempre o que o crawler ve.
- Se velocidade de indexacao importa, prefira SSR ou SSG.
- Deixe CSR para interacao, nao para a base semantica da pagina.
- Use dynamic rendering so quando arquitetura ou legado empurrarem voce para isso.
No fluxo de revisao, SEO Analyzer ajuda a verificar se o HTML inicial ja entrega o minimo essencial. E o Meta-Tag Generator e util para travar snippet e sinais basicos antes da publicacao.
Fechando
Esse experimento nao prova que JavaScript "estraga SEO". O que ele prova e mais chato: depender do cliente para expor o conteudo principal ainda te deixa sujeito a atraso, diferenca entre motores e indexacao menos previsivel.
Se quiser uma regra simples, ela e esta: deixe a camada rica de experiencia para o JavaScript, mas entregue o significado SEO da pagina em HTML desde o inicio. Quase sempre esse e o caminho menos arriscado.