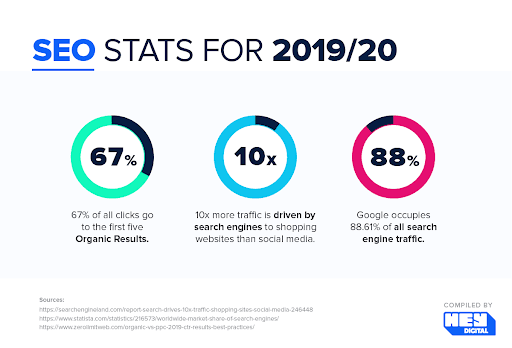
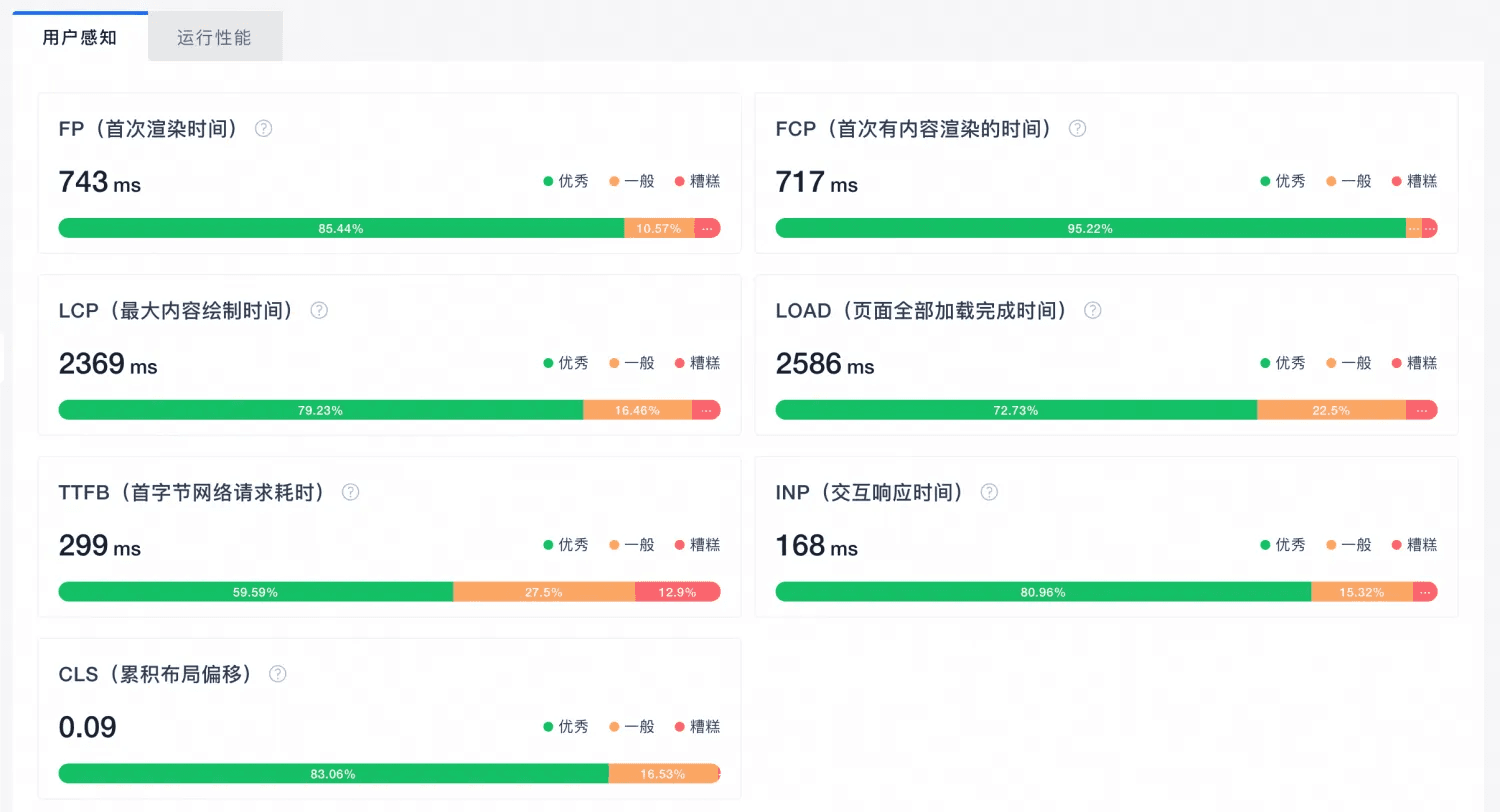
Nem todo site precisa tratar crawl budget como prioridade máxima. Se o projeto é pequeno, tem poucas URLs, estrutura limpa e novas páginas entram rápido no radar do Google, normalmente existem gargalos mais urgentes para resolver.
O cenário muda quando o site cresce e começa a acumular filtros, parâmetros, redirecionamentos antigos, páginas fracas, duplicatas e rotas profundas demais. A partir daí, o Googlebot passa a gastar tempo onde não deveria.
Em outras palavras: quanto mais rastreamento é gasto em URLs erradas, menos sobra para as páginas que trazem tráfego qualificado e conversão.
O que crawl budget significa na prática
O Google já deixou claro que "crawl budget" não é uma única métrica isolada. Ainda assim, existe uma realidade operacional: o buscador não rastreia tudo com a mesma frequência nem com a mesma prioridade.
Na prática, entram duas forças:
- quanto o seu servidor aguenta receber sem degradação
- quanto o Google sente necessidade de voltar a determinadas URLs
Quando a casa está organizada, isso funciona bem. Quando o site produz ruído demais, o orçamento se espalha.
Quando vale se preocupar de verdade
O tema pesa mais em sites como estes:
- ecommerce com navegação facetada
- diretórios, marketplaces e catálogos grandes
- blogs com muito arquivo antigo e pouco mantido
- sites multilíngues ou multi-região
- projetos muito dependentes de JavaScript
- migrações com sobras de redirecionamento e páginas órfãs
Os sintomas clássicos:
- páginas importantes demoram para indexar
- Search Console mostra rastreamento excessivo em URLs secundárias
- os logs revelam muitos 404, 5xx e cadeias de redirecionamento
- o Google visita mais páginas inúteis do que páginas estratégicas
Onde o crawl budget mais se perde
Os vazamentos mais comuns costumam vir de problemas conhecidos.
1. Servidor lento
Se o TTFB é alto ou o servidor oscila quando o bot aumenta a intensidade, o Google tende a reduzir o ritmo.
2. Erros e redirecionamentos desnecessários
4xx, 5xx e rotas A -> B -> C consomem rastreamento sem gerar nenhum ganho.
3. URLs duplicadas ou quase duplicadas
Filtros, parâmetros, páginas de ordenação, tracking, HTTP/HTTPS mal resolvido, canonicals inconsistentes. Tudo isso infla a superfície de rastreamento.
4. Arquitetura interna fraca
Se uma página relevante está enterrada demais, o sinal que ela passa é simples: não parece prioridade.
5. Armadilhas para crawler
Calendários infinitos, busca interna indexável, facetas sem limite e rotas dinâmicas sem valor próprio.

Comece limpando performance e saúde técnica
Antes de tentar "ganhar mais crawl", é melhor parar de desperdiçar o que já existe.
- diminua o TTFB
- reduza redirecionamentos desnecessários
- corrija 4xx e 5xx persistentes
- garanta que CSS, JS e imagens importantes retornem 200
- verifique se o
robots.txtnão está bloqueando recursos críticos
Uma passada pelo SEO Analyzer ajuda a achar esses gargalos repetidos com rapidez. Se o problema estiver nas regras de acesso para bots, o Gerador de Robots.txt ajuda a reorganizar isso.
Mostre com clareza quais páginas merecem prioridade
O Google não depende do que você diz que é importante. Ele depende do que a estrutura do site sugere.
Aproxime páginas-chave da superfície
Páginas que geram negócio, leads ou tráfego forte não deveriam viver escondidas.
- coloque links a partir de hubs e categorias
- use páginas fortes como distribuidores de autoridade
- evite depender só de links contextuais perdidos no meio do conteúdo
Mantenha o sitemap sob controle
Sitemap XML não é depósito de tudo o que existe. Ele deve refletir o conjunto de URLs que realmente faz sentido rastrear e indexar. Se precisar reestruturar isso, use o Gerador de Sitemap.
Encontre páginas órfãs
Uma página órfã ainda pode ser acessada por links antigos ou pelo sitemap. Mas, sem links internos, ela perde contexto e prioridade. Se ainda gera tráfego, pior ainda: você tem uma página útil fora da malha principal de descoberta.
Canonical e duplicação: o desperdício silencioso
Muita perda de crawl budget nasce do excesso de versões para a mesma intenção.
Vale revisar:
- filtros e ordenações
- parâmetros de campanha
- duplicatas com e sem slash
- HTTP contra HTTPS
- categorias muito parecidas
Quando o Google rastreia várias versões para acabar escolhendo uma só, há desperdício claro. Dá para revisar essas sinalizações com o Gerador de Tags Canonical.
Conteúdo também pesa na decisão de rastreamento
O Google não olha só para a técnica. Ele tenta entender quais páginas valem revisita.
Páginas rasas, repetitivas ou largadas tendem a perder importância. Páginas úteis, atualizadas e consistentes tendem a ganhar mais atenção.

Isso não significa aumentar texto por aumentar. Significa fortalecer as páginas que realmente sustentam a estratégia:
- unir conteúdos fracos e sobrepostos
- atualizar páginas com valor comercial
- remover ou redirecionar URLs sem utilidade real
Profundidade de clique ainda importa muito
Se uma página fica longe demais da home, o Google tende a tratá-la como menos prioritária.

Se suas páginas ativas ou "money pages" estão escondidas, vale reorganizar:
- criar hubs temáticos
- reforçar categorias principais
- incluir sitemap HTML para conjuntos profundos
- evitar esconder conteúdo importante atrás de busca interna ou filtros JS
Um plano prático para agir
Se quiser atacar o problema com método, siga esta ordem:
- Veja as estatísticas de rastreamento no Search Console.
- Analise logs se o site já tiver volume suficiente.
- Corrija erros e cadeias de redirecionamento.
- Consolide duplicatas e ajuste canonicals.
- Reduza armadilhas e parâmetros desnecessários.
- Reforce links internos para páginas estratégicas.
- Alinhe o sitemap às URLs que importam.
- Atualize páginas fortes e aposente páginas fracas.
Resumindo
O objetivo não é conseguir "mais rastreamento" por vaidade. O objetivo é tirar desperdício do caminho para que o Google volte mais vezes às páginas certas.
Menos ruído técnico, menos duplicidade, mais clareza estrutural. É daí que normalmente vem a melhora.