Le JavaScript n'est pas le probleme. Le vrai probleme, c'est de supposer que tous les moteurs vont interpreter une page JS-heavy avec la meme aisance qu'un navigateur moderne. En pratique, ce n'est pas si simple.
Cet article s'appuie sur un test volontairement concret : une page dont les elements SEO importants dependaient presque entierement d'un rendu JavaScript cote client. L'objectif etait simple : voir ce que chaque moteur prenait en compte, quand il le faisait, et ou les limites apparaissaient vraiment.
Si vous travaillez avec React, Vue, Next.js, Nuxt ou n'importe quelle architecture hybride, ce sujet vous concerne directement. Et si vous voulez verifier ce qu'un crawler voit reellement avant mise en ligne, SEO Analyzer est un bon point d'entree pour comparer HTML initial, rendu final et signaux techniques.
D'abord, la logique des deux vagues d'indexation
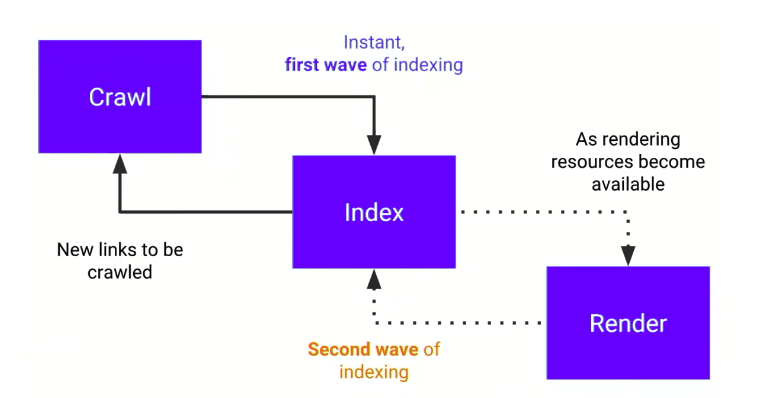
Google ne traite pas toujours une page JavaScript en un seul passage. Le schema le plus courant ressemble a ceci :
- Google recupere et indexe d'abord le HTML initial.
- Plus tard, quand les ressources de rendu sont disponibles, il execute le JavaScript et reevalue le DOM final.
Ce detail change beaucoup de choses. Si le contenu critique n'existe qu'apres execution du JS, il rate la premiere vague.
C'est exactement ce qui explique les snippets bizarres qu'on voit parfois au debut, avant qu'ils ne se corrigent quelques jours plus tard. Ou pas.
Comment l'experience a ete construite
La page test etait volontairement extreme :
- HTML initial minimal
title,H1, description et corps de texte injectes par JavaScript- contenu charge via AJAX
- schema
Articleajoute lui aussi en JS
Autrement dit, sans rendu JavaScript, le moteur n'avait presque rien de solide a exploiter.
1$(document).ready(function () { 2 $.ajax({ 3 url: '/api/get-article-data', 4 success: function(data) { 5 $('title').text(data.title); 6 $('h1#main-title').text(data.h1); 7 $('meta[name="description"]').attr('content', data.description); 8 $('#article-content').html(data.body); 9 10 var script = document.createElement('script'); 11 script.type = 'application/ld+json'; 12 script.text = JSON.stringify(data.schemaData); 13 document.head.appendChild(script); 14 } 15 }); 16});
L'idee etait de rendre le contenu final tres different du HTML de depart. Comme ca, au moindre changement dans la SERP, on pouvait savoir si le rendu avait reellement eu lieu.
Ce que les outils Google etaient capables de voir
Avant meme d'observer la SERP, les tests de rendu donnaient deja un indice utile. Le Rich Results Test de Google reconstituait bien le DOM final et detectait les elements injectes par JavaScript.
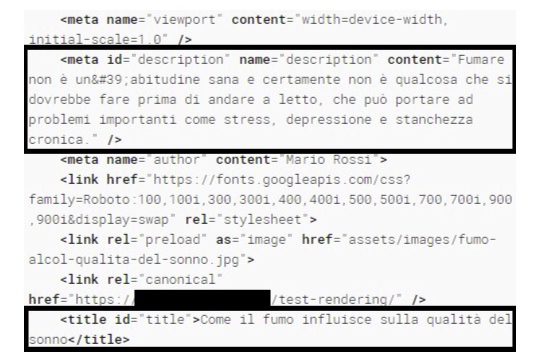
Autrement dit, Google savait techniquement lire la page. Mais entre "savoir lire" et "integrer rapidement dans l'index", il y a encore de la distance.
Premiere vague : ce qui est apparu au debut
Quelques heures apres soumission, la page etait deja visible dans Google, Bing et Yandex. Sauf que les titres et descriptions affiches venaient du HTML initial, pas du contenu genere plus tard par JS.
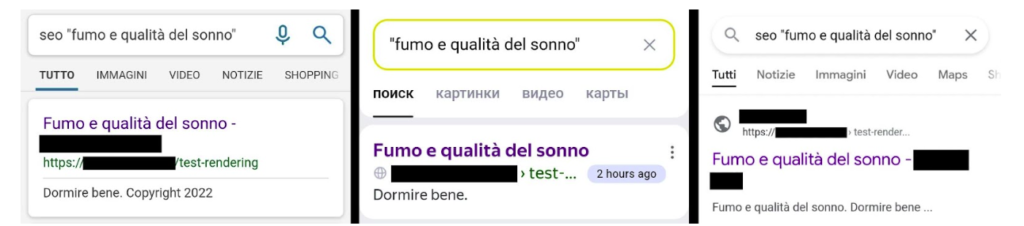
La demonstration est nette : la page est indexee, oui, mais pas encore dans sa forme complete.
Pour le SEO, c'est sensible des que vous dependez de delais courts :
- actualites
- nouvelles landing pages
- contenus promo temporaires
- publications a valeur immediate
Deuxieme vague : Google finit par suivre, avec retard
Quelques jours plus tard, une requete site: montrait bien du texte qui, a l'origine, n'existait que dans le rendu JavaScript. Google avait donc fini par integrer le contenu final.
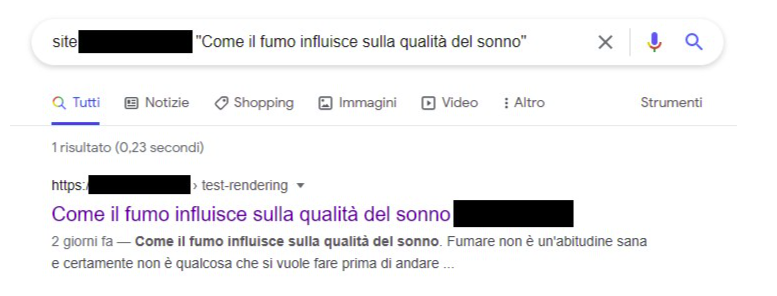
La conclusion est importante : Google peut traiter du contenu client-side, y compris charge via AJAX. Mais il le fait dans un second temps, pas en instantane.
Selon le projet, ce delai est tolerable ou non. C'est la vraie question.
Bing et Yandex : la limite apparait vite
Pendant le test, Bing et Yandex sont restes beaucoup plus colles au HTML initial. Leur comportement etait clairement moins souple que celui de Google sur ce scenario de rendu.
Ce n'est pas anecdotique. Des qu'on travaille en dehors d'un raisonnement "Google only", les differences de capacite de rendu comptent encore beaucoup.
Et sur des marches ou d'autres moteurs ont encore du poids, une page trop dependante du client-side rendering peut perdre bien plus que ce que l'equipe avait anticipe.
La parade intermediaire : le dynamic rendering
Un autre test a consisté a servir une version pre-rendue aux crawlers :
- navigateur utilisateur : page normale avec JS
- crawler : HTML deja rendu
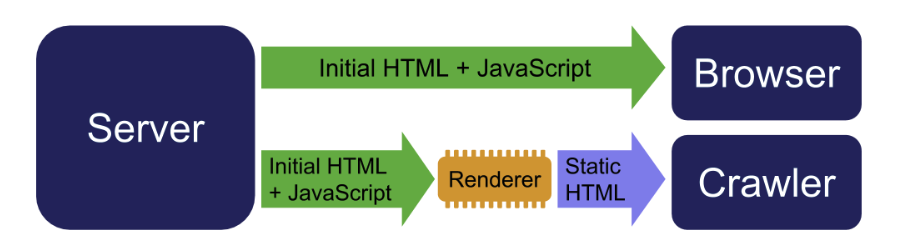
Une fois ce mecanisme active, Yandex a fini par mettre a jour son snippet avec le contenu pre-rendu.

Ce n'est pas une raison pour faire du dynamic rendering partout. Mais c'est une tres bonne preuve de terrain : plus on donne tot un HTML interpretable au moteur, moins on se bat contre le rendu.
Ce que ce test montre clairement
1. Oui, Google sait gerer le JavaScript. Non, cela ne supprime pas le risque SEO
Le raccourci habituel, c'est : "Google render JS, donc on peut tout laisser au client". C'est trop optimiste.
Google sait rendre, mais :
- il y a une file d'attente
- il y a un delai
- toutes les pages ne sont pas traitees a la meme vitesse
- les elements critiques perdent en immediate si on les sort du HTML initial
2. Le HTML initial reste la couche de securite
Si une page compte pour le SEO, il vaut mieux que ces elements soient deja presents des la premiere reponse :
<title>- meta description
- H1
- texte principal
- liens importants
- donnees structurees utiles
C'est le moyen le plus stable de rester lisible, moteur apres moteur.
3. SSR ou SSG restent les approches les plus sereines
Quand l'architecture le permet, SSR ou SSG restent des choix plus robustes pour le contenu critique. Pas parce que CSR serait interdit, mais parce que ce n'est pas la meilleure place pour stocker la substance SEO de la page.
4. Le dynamic rendering est un contournement, pas un ideal
Il peut sauver une stack legacy ou une migration difficile. Mais il ajoute de la complexite et demande une discipline technique serieuse pour eviter les incoherences entre version bot et version utilisateur.
Recommandations concretes
Si on transforme ce test en regles de travail, cela donne plutot ceci :
- Ne laissez pas le contenu SEO critique dependre uniquement du rendu client.
- Testez ce que le crawler lit vraiment.
- Si l'indexation rapide compte, privilegiez SSR ou SSG.
- Gardez CSR pour l'interaction, pas pour la charpente semantique.
- Utilisez le dynamic rendering seulement si votre contexte technique vous y pousse.
Pour les controles rapides avant ou apres deploiement, SEO Analyzer aide a verifier ce qui sort vraiment dans le HTML initial. Et pour les snippets, le Meta-Tag Generator reste pratique pour verrouiller les bases.
Conclusion
Le JavaScript n'est pas l'ennemi du SEO. Ce qui cree le risque, c'est de confier a une seconde vague de rendu tout ce qui donne son sens a la page.
La regle la plus simple reste souvent la meilleure : gardez l'interactivite riche en JavaScript, mais mettez le sens SEO critique dans le HTML des le depart. C'est plus lisible pour Google, plus stable pour les autres moteurs, et beaucoup moins stressant pour l'equipe.


