JavaScript ist aus modernen Websites nicht wegzudenken. Das Problem beginnt dort, wo Teams daraus stillschweigend ableiten, dass Suchmaschinen schon irgendwie mitkommen werden. Manchmal tun sie das. Manchmal zu spät. Manchmal gar nicht.
Genau darum geht es in diesem Experiment. Nicht um Theorie, sondern um eine konkrete Frage: Was passiert, wenn zentrale Inhalte fast ausschließlich clientseitig per JavaScript ins DOM geschrieben werden?
Wenn du mit React, Vue, Next.js, Nuxt oder einem klassischen CSR-Setup arbeitest, ist das kein Randthema. Und wenn du vor dem Go-Live prüfen willst, was von einer Seite wirklich bei Crawlern ankommt, ist SEO Analyzer ein brauchbarer Startpunkt, um HTML-Ausgabe und technische Signale gegenzuprüfen.
Die Basis: Googles Two-Wave Indexing
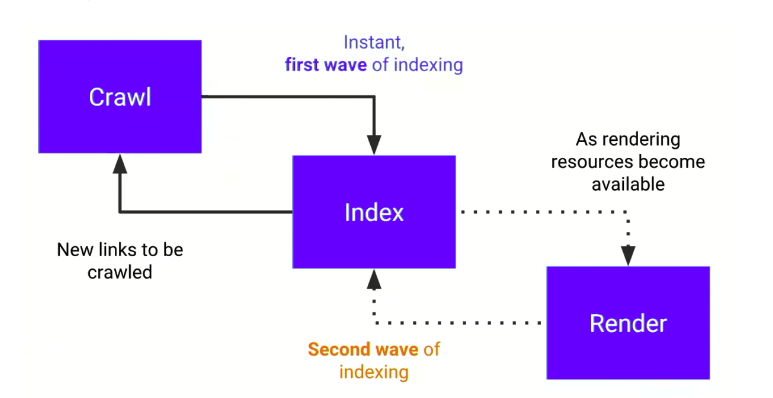
Google verarbeitet JavaScript-lastige Seiten typischerweise nicht in einem Schritt, sondern in zwei Wellen:
- Zuerst wird das initiale HTML gecrawlt und indexiert.
- Danach wird die Seite, sobald Rendering-Ressourcen frei sind, gerendert und mit dem finalen DOM erneut bewertet.
Das klingt erstmal sauber, hat aber Folgen. Alles, was erst nach der JS-Ausführung sichtbar wird, fehlt in der ersten Welle.
Deshalb tauchen neue Seiten manchmal zunächst mit merkwürdigen Snippets, unvollständigen Titeln oder generischen Texten in der Suche auf und korrigieren sich erst Tage später.
So war der Test aufgebaut
Die Testseite war absichtlich radikal:
- minimales initiales HTML
title,H1, Description und Hauptinhalt erst per JavaScript- Inhalte per AJAX nachgeladen
Article-Schema ebenfalls per JS injiziert
Mit anderen Worten: Wenn ein Crawler kein JavaScript rendert, bleibt fast nichts Wertvolles übrig.
1$(document).ready(function () { 2 $.ajax({ 3 url: '/api/get-article-data', 4 success: function(data) { 5 $('title').text(data.title); 6 $('h1#main-title').text(data.h1); 7 $('meta[name="description"]').attr('content', data.description); 8 $('#article-content').html(data.body); 9 10 var script = document.createElement('script'); 11 script.type = 'application/ld+json'; 12 script.text = JSON.stringify(data.schemaData); 13 document.head.appendChild(script); 14 } 15 }); 16});
Der Versuchsaufbau war bewusst so gewählt, dass sich gerenderter Inhalt und Initial-HTML deutlich unterscheiden. Sobald sich Snippets in der Suche ändern, sieht man sofort, ob Rendering tatsächlich stattgefunden hat.
Was Googles eigene Tools rendern konnten
Bevor man die Suchergebnisse bewertet, lohnt sich ein Blick auf kontrollierte Tests. In diesem Fall konnte Googles Rich Results Test das DOM erfolgreich rendern und die per JavaScript ergänzten Elemente auslesen.
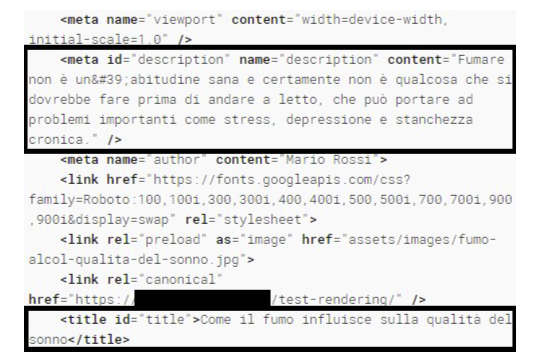
Das ist ein wichtiger Hinweis, aber eben nur ein Hinweis. "Kann rendern" ist nicht dasselbe wie "rendert sofort im Live-Index".
Erste Welle: Was zunächst in der SERP erschien
Wenige Stunden nach dem Einreichen war die Seite bereits bei Google, Bing und Yandex auffindbar. Nur stammten Titel und Beschreibung noch aus dem mageren Initial-HTML, nicht aus dem per JS aufgebauten Inhalt.
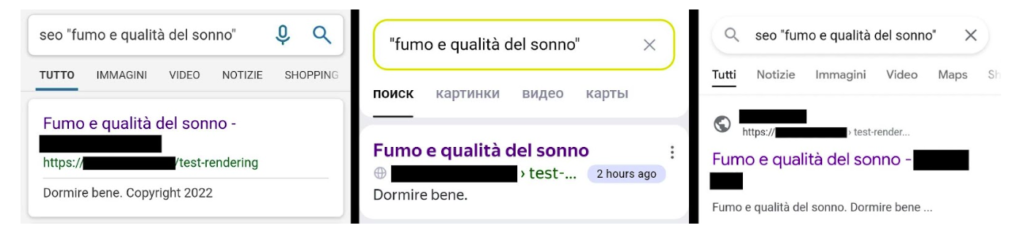
Das ist die erste Indexierungswelle in Reinform. Die Seite ist "drin", aber noch nicht so, wie Nutzer sie nach vollständigem Laden tatsächlich sehen.
Für SEO wird das dann problematisch, wenn du auf schnelle Aufnahme angewiesen bist, etwa bei:
- News
- frischen Landingpages
- Kampagnen-URLs
- zeitkritischen Inhalten
Zweite Welle: Google holt nach, aber nicht sofort
Nach einigen Tagen zeigte eine site:-Abfrage schließlich Text, der ursprünglich nur nach der JavaScript-Ausführung vorhanden war. Google hatte den gerenderten Inhalt also übernommen.
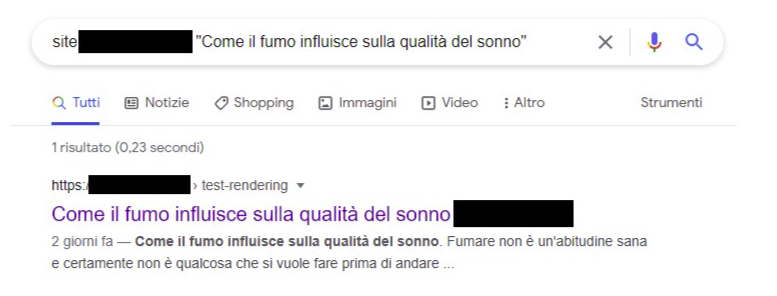
Die Schlussfolgerung ist ziemlich klar: Google kann clientseitig gerenderten Content verarbeiten, auch wenn er erst per AJAX nachgeladen wird. Aber diese Verarbeitung hängt an der zweiten Welle und kommt nicht sofort.
Für manche Projekte ist das akzeptabel. Für andere ist es unnötiges Risiko.
Bing und Yandex: Genau hier wird der Unterschied sichtbar
Im selben Test kamen Bing und Yandex deutlich schlechter mit dem clientseitigen Rendering zurecht. Sie blieben viel stärker am Initial-HTML hängen.
Das ist kein exotischer Sonderfall. Wer schon einmal außerhalb des reinen Google-Kosmos JS-lastige Seiten optimieren musste, kennt dieses Muster. Rendering-Fähigkeiten unterscheiden sich spürbar, und in regional geprägten Märkten macht das echte Unterschiede.
Sich allein auf "Google kann das schon" zu verlassen, greift also oft zu kurz.
Dynamic Rendering als Fallback
Als zusätzlicher Test wurde Dynamic Rendering eingerichtet. Das Prinzip:
- normale Browser bekommen die übliche JS-Seite
- Suchmaschinen-Crawler bekommen eine vorgerenderte HTML-Version
Nachdem diese Variante aktiv war, aktualisierte Yandex den Ausschnitt und zog den vorgerenderten Inhalt korrekt heran.

Das heißt nicht, dass Dynamic Rendering automatisch die beste Lösung ist. Aber es zeigt ziemlich deutlich, was Suchmaschinen bevorzugen: sofort lesbares HTML.
Was man aus dem Test mitnehmen sollte
1. Google kann JS, aber das beseitigt nicht das SEO-Risiko
Viele hören "Google rendert JavaScript" und lesen daraus "Dann ist die Auslieferungsform egal". Genau das stimmt nicht.
Google kann rendern, ja. Aber:
- es gibt Warteschlangen
- es gibt Verzögerungen
- nicht jede Seite wird gleich schnell nachverarbeitet
- kritische Inhalte verlieren an Unmittelbarkeit, wenn sie nicht im Initial-HTML stehen
2. Das Initial-HTML bleibt deine Absicherung
Für SEO-kritische Seiten gehören diese Elemente möglichst in die erste HTML-Antwort:
<title>- Meta Description
- H1
- zentraler Seitentext
- wichtige Links
- relevantes strukturiertes Markup
Das funktioniert über Suchmaschinen hinweg stabiler und reduziert unnötige Abhängigkeit vom Rendering.
3. SSR und SSG sind weiter die robustere Wahl
Wenn du technischen Spielraum hast, sind SSR oder SSG für kritische Inhalte meist die solidere Entscheidung. Nicht weil CSR grundsätzlich schlecht wäre, sondern weil du Titel, Descriptions und Hauptcontent nicht in eine nachgelagerte Rendering-Warteschlange schieben solltest.
4. Dynamic Rendering ist eher Übergang als Zielbild
Für Alt-Systeme oder schwierige Migrationen kann es helfen. Für neue Projekte würde ich es eher als Notlösung sehen. Es erhöht den Betriebsaufwand und verlangt saubere Kontrolle, damit keine problematischen Abweichungen zwischen Nutzer- und Bot-Version entstehen.
Konkrete Empfehlungen für SEO- und Dev-Teams
Wenn man das Ganze runterbricht, bleiben ein paar recht nüchterne Regeln:
- Lagere keine SEO-kritischen Inhalte ausschließlich in clientseitiges JS aus.
- Prüfe immer, was Crawler wirklich sehen.
- Nutze SSR oder SSG, wenn Inhalte schnell und zuverlässig indexiert werden sollen.
- Nutze CSR eher für Interaktion, nicht für semantische Grundsubstanz.
- Ziehe Dynamic Rendering nur dann in Betracht, wenn Architektur oder Legacy dich dazu zwingen.
Zur Prüfung nach Deployments kannst du mit SEO Analyzer schnell erkennen, ob Initial-HTML, Indexierbarkeit und Render-Signale sauber rausgehen. Für Snippets und Seitensignale lohnt sich zusätzlich der Meta-Tag Generator.
Fazit
Das Experiment zeigt nicht, dass JavaScript schlecht für SEO ist. Es zeigt etwas Präziseres: Wenn deine wichtigsten Inhalte erst nach clientseitigem Rendering erscheinen, machst du dich abhängig von Verzögerungen, von Suchmaschinen-Unterschieden und von Optimismus.
Wenn du es pragmatisch halten willst, dann so: Interaktive Erlebnisse gern mit JavaScript, aber SEO-kritische Bedeutung möglichst schon im HTML. Genau dort wird aus einer hübschen Frontend-Lösung eine suchmaschinentaugliche Seite.